


北大张大庆教授:无线感知赋予具身智能“第六感官”,6G时代手机隔空测心跳
毫无疑问,具身智能已成为时下最流行的技术趋势之一。但相较于人类基础能力,如大脑、耳目和四肢的协同,机器人执行物理任务时仍然显得笨拙。△来源新火种智库《中国AIGC产业全景报告》如何让机器人更灵活的「动」起来?作为一切行为的起点,感知系统就显得尤为关键。
毫无疑问,具身智能已成为时下最流行的技术趋势之一。但相较于人类基础能力,如大脑、耳目和四肢的协同,机器人执行物理任务时仍然显得笨拙。△来源新火种智库《中国AIGC产业全景报告》如何让机器人更灵活的「动」起来?作为一切行为的起点,感知系统就显得尤为关键。

每经AI快讯,北京大学计算中心发布通知,北大本地化部署的deepseek满血版R1和V3已深度适配教学应用场景,向校内多项人工智能应用北大问学、AIMD、化小北、金融AI助教提供服务。每日经济新闻

北京大学与腾讯等机构的研究者们提出了多模态对齐框架 ——LanguageBind。该框架在视频、音频、文本、深度图和热图像等五种不同模态的下游任务中取得了卓越的性能,刷榜多项评估榜单,这标志着多模态学习领域向着「大一统」理念迈进了重要一步。在现代社会,信息传递和交流不再局限于单一模态。

混合专家(MoE)架构已支持多模态大模型,开发者终于不用卷参数量了!北大联合中山大学、腾讯等机构推出的新模型MoE-LLaVA,登上了GitHub热榜。它仅有3B激活参数,表现却已和7B稠密模型持平,甚至部分指标比13B的模型还要好。

AI 科技评论报道编辑 | 陈大鑫近日,由北京大学崔斌教授数据与智能实验室( Data and Intelligence Research LAB, DAIR)开发的通用黑盒优化系统 OpenBox 开源发布!相比于SMAC3,Hyperopt等现有开源系统,OpenBox支持更通用的黑盒优化场景,
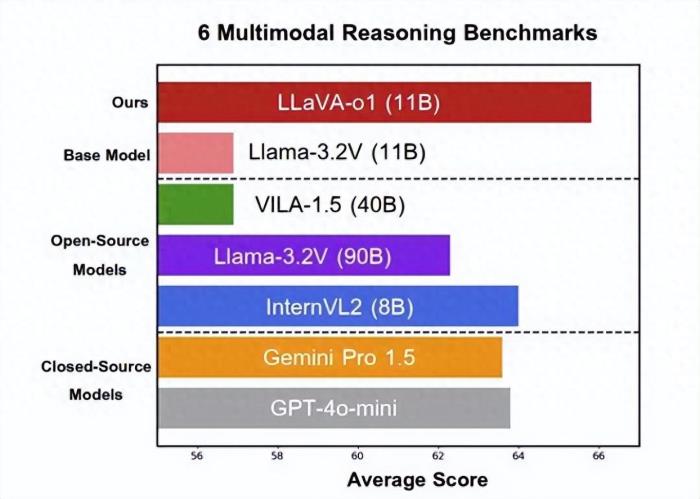
北大等出品,首个多模态版o1开源模型来了——代号LLaVA-o1,基于Llama-3.2-Vision模型打造,超越传统思维链提示,实现自主“慢思考”推理。在多模态推理基准测试中,LLaVA-o1超越其基础模型8.9%,并在性能上超越了一众开闭源模型。新模型具体如何推理,直接上实例,比如问题是:传统

北京大学和中山大学等机构研究者提出了统一的视觉语言大模型 ——Chat-UniVi。通过构建图片和视频统一表征,该框架使得一个 LLM 能够在图片和视频的混合数据下训练,并同时完成图片和视频理解任务。更重要的是,该框架极大降低了视觉语言模型训练和推理的开销,

想象一下当你躺在沙发上,只需要不假思索地说出指令,机器人就能帮你干活,是不是听起来就十分惬意?如今这种科幻电影中的场景正在变为现实,来自北京大学的助理教授、博士生导师董豪团队近日提出首个通用指令导航大模型系统InstructNav。不论是寻找物体,走到指定位置,还是满足抽象的人类需求,只要你说出指令

人民财讯3月21日电,3月17日至21日,2025 NVIDIA GTC(英伟达GPU技术大会)在美国加州圣何塞召开。在本次GTC大会上,协鑫集团联合北京大学、NVIDIA达成产学研深度协同,联合推出基于NVIDIA Earth-2平台的光伏功率预测大模型,这标志着能源行业智能化转型取得突破性进展。
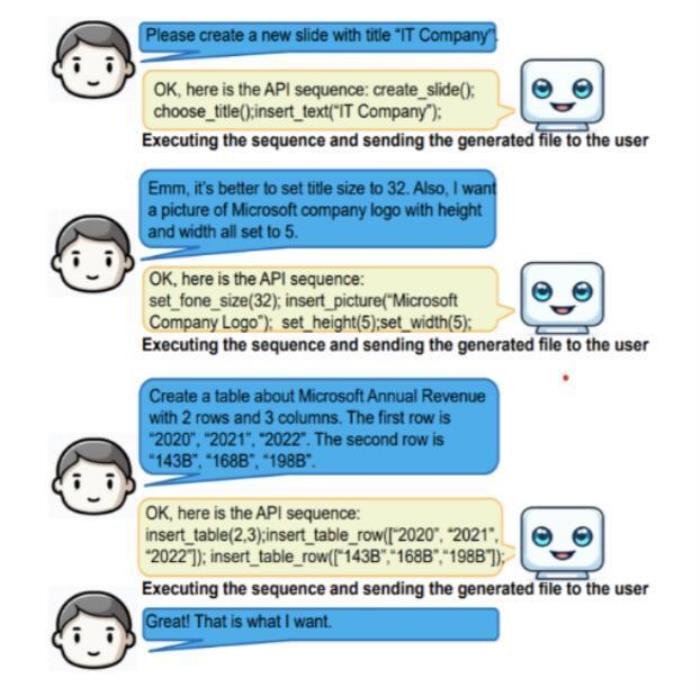
DoNews11月7日消息,据品玩引述 HuggingFace 页面报道,微软研究院联手北京大学,共同发布了一款名为 PPTC 的大模型测试基准,可以用于测试大模型在PPT 生成方面的能力。研究团队表示,PPTC包含 279 个涵盖不同主题的多回合会话和数百条涉及多模式操作的说明。研究团队还提出了P










