

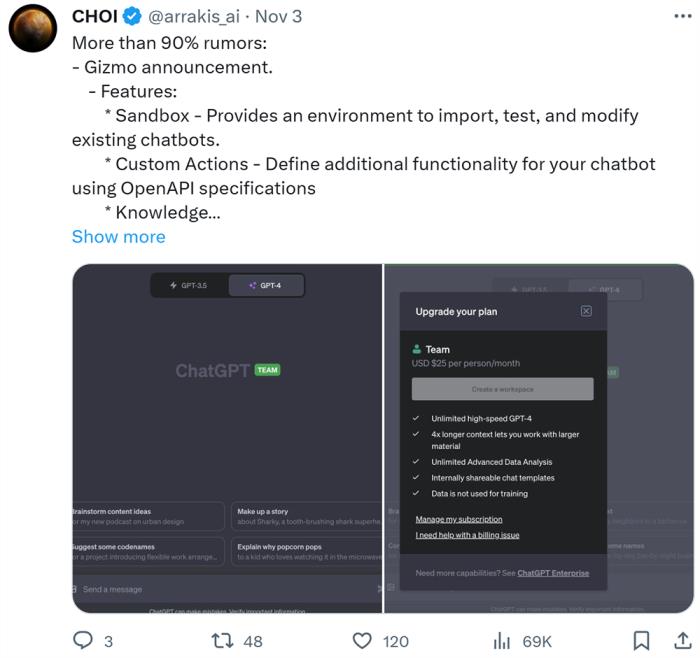
OpenAI首届开发者大会内容曝光;马斯克xAI大模型进展公布;中国第二批大模型备案获批丨AIGC大事日报
1、OpenAI首届开发者大会内容曝光2、马斯克xAI推出首个AI聊天机器人Grok3、李开复AI公司首发大模型 传阿里云领投4、360奇元大模型通过备案落地5、昆仑万维“天工”大模型通过备案6、有道“子曰”教育大模型通过备案7、学而思MathGPT大模型全面开放 将落地学习机8、知乎“知海图AI”
1、OpenAI首届开发者大会内容曝光2、马斯克xAI推出首个AI聊天机器人Grok3、李开复AI公司首发大模型 传阿里云领投4、360奇元大模型通过备案落地5、昆仑万维“天工”大模型通过备案6、有道“子曰”教育大模型通过备案7、学而思MathGPT大模型全面开放 将落地学习机8、知乎“知海图AI”

《科创板日报》11月24日讯 本周AI大模型周报主要内容有:李彦宏表示,文心大模型重构后的广告系统 将在四季度带来数亿元增量收入;快手高管称,正研发超千亿规模和多模态大模型……▍OpenAI的“宫斗”最终以奥特曼的回归落幕11月22日,OpenAI在社交平台X上宣布,已经原则上达成协议,奥特曼重返公

财联社|元宇宙NEWS 5月18日讯 今日新鲜事有:科大讯飞董事长刘庆峰:讯飞星火大模型10月实现中文超越ChatGPT在第七届世界智能大会上,科大讯飞董事长刘庆峰在现场演讲中表示,认知大模型已经成为通用人工智能的曙光,目前纯大模型仍存在缺陷,包括无法及时更新知识、事实类问答容易“张冠李戴”、对传统

财联社5月22日电,快手科技创始人兼首席执行官程一笑在今日业绩电商上透露,在预训练阶段数据和模型架构优化的基础上,通过在反馈强化学习RLHF方面的技术突破,使得快手的1750亿规模大语言模型在更新迭代后的综合性能已经接近GPT4.0的水平。(记者 徐赐豪)

2月18日,阶跃星辰和吉利汽车集团联合宣布,将双方合作的阶跃两款Step系列多模态大模型向全球开发者开源。其中,包含开源视频生成模型阶跃Step-Video-T2V,以及语音交互大模型阶跃Step-Audio。这是阶跃星辰首次宣布开源其Step系列基座模型。据介绍,阶跃Step-Video-T2V模

10月24日,第六届世界声博会暨2023科大讯飞全球1024开发者节在合肥启幕,如期升级发布讯飞星火认知大模型V3.0。“星火认知大模型V3.0已整体超越ChatGPT,并在医疗领域超越GPT-4。2024年上半年,讯飞星火V4.0将发布,对标GPT-4。”科大讯飞董事长刘庆峰表示,大模型时代的序幕

上周五,全球最大的开源大模型社区Hugging Face公布了最新的开源大模型排行榜,阿里云通义千问Qwen-72B表现抢眼,以73.6的综合得分在所有预训练模型中排名第一,超越Llama2登顶榜首。

大模型近年来,随着计算机技术和大数据的快速发展,深度学习在各个领域取得了显著的成果。为了提高模型的性能,研究者们不断尝试增加模型的参数数量,从而诞生了大模型这一概念。本文将从大模型的原理、训练过程、prompt和相关应用介绍等方面进行分析,帮助读者初步了解大模型。

当红的AI大模型市场风起云涌,作为数字化基础较为完善的金融保险业,正加速大模型应用落地。年内中国太保、众安保险、阳光保险等险企均公布了布局的新动作;科技公司也在加速大模型布局,并已运用在保险领域。

12月9日,据媒体消息称,前百川智能联合创始人、商业化负责人洪涛已经离职。据百川智能官方回复称,“洪涛因个人原因已从公司离职。在公司创立初期,他快速搭建了商业化团队,为公司发展奠定了基础。我们非常感谢他的付出和贡献。”公开资料显示,洪涛毕业于清华大学,于2005年加入搜狗公司,此前任原搜狗CMO,与










