

史上最严中文真实性评估:OpenAIo1第1豆包第2,其它全部不及格
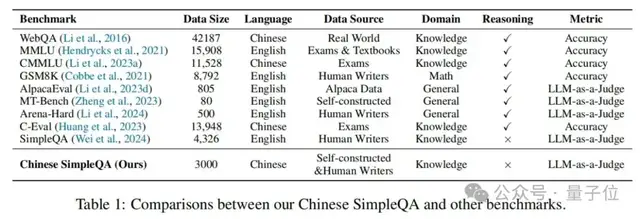
新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。近日,淘宝天猫集团的研究者们提出了中文简短问答(Chinese SimpleQA),这是首个全面的中文基准,具有“中文、多样性、高质量、静态、易于评估”五个特性,用于评估语言模型回答简短问题的真实性能力。研究人员表示,中文简短问答
新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。近日,淘宝天猫集团的研究者们提出了中文简短问答(Chinese SimpleQA),这是首个全面的中文基准,具有“中文、多样性、高质量、静态、易于评估”五个特性,用于评估语言模型回答简短问题的真实性能力。研究人员表示,中文简短问答

3月6日消息,以DeepSeek为代表的AI大模型,正在以前所未有的速度进入人们的日常生活和工作。但你有没有发现,当你在使用AI时候,它会胡编乱造,凭空捏造细节?事实上,在大家沉浸在AI带来的效率和便利的同时,杜撰和造假已经成为当下AI最大的槽点。










