新火种
2023-10-28
新火种
2023-10-28 


CogVLM:智谱AI新一代多模态大模型
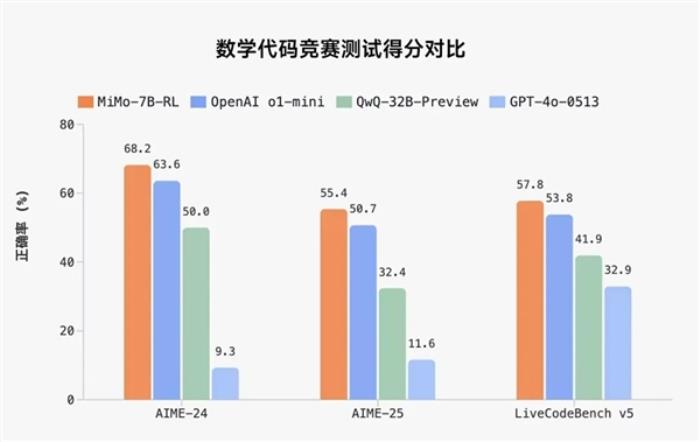
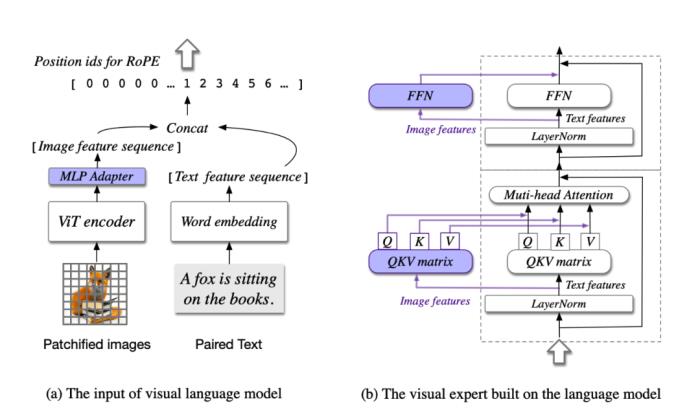
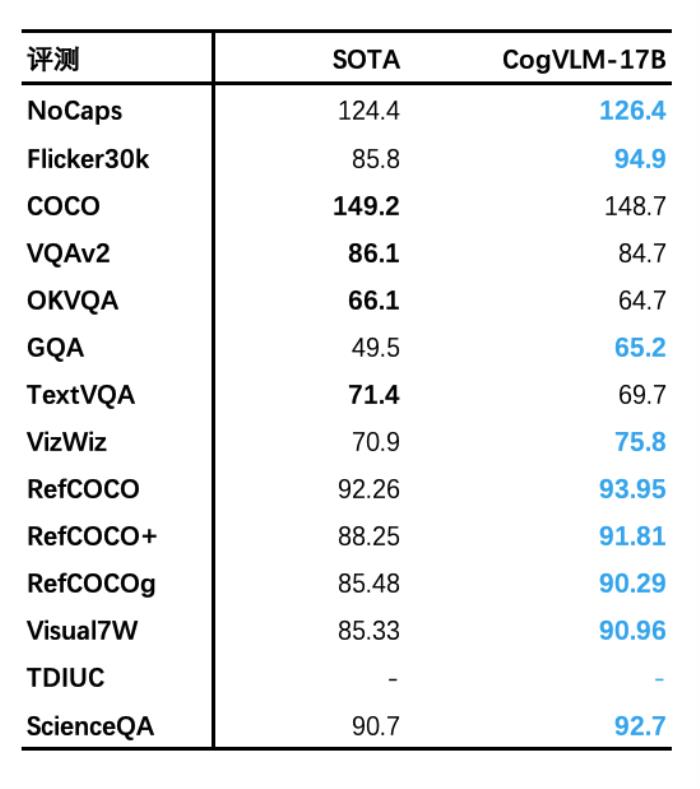
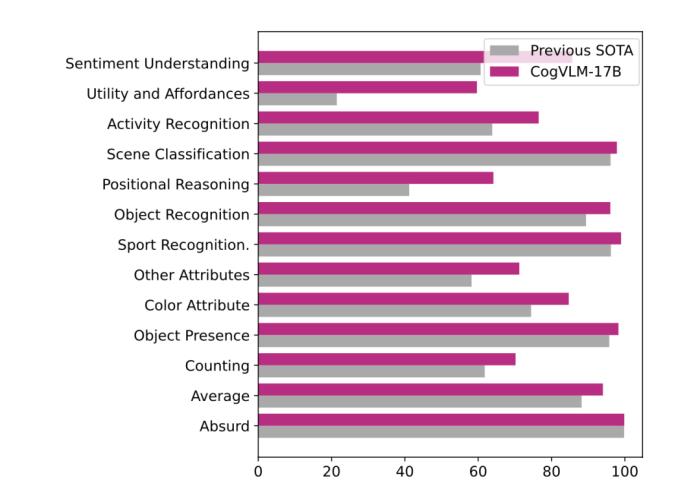
自 5 月 18 日发布并开源 VisualGLM-6B 以来,智谱AI&清华KEG潜心打磨,致力于开发更加强大的多模态大模型。基于对视觉和语言信息之间融合的理解,我们提出了一种新的视觉语言基础模型 CogVLM。CogVLM 可以在不牺牲任何 NLP 任务性能的情况下,实现视觉语言特征的深度融合。我们训练的 CogVLM-17B是目前多模态权威学术榜单上综合成绩第一的模型,在14个数据集上取得了state-of-the-art或者第二名的成绩。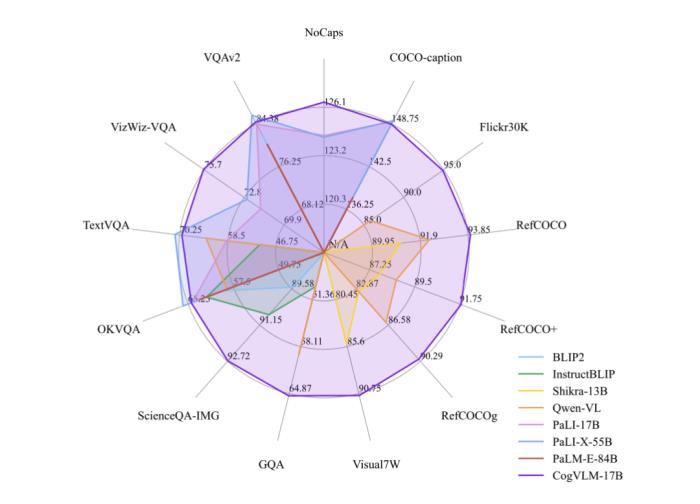 我们可以初步体验 CogVLM 的效果:
我们可以初步体验 CogVLM 的效果:
我们可以初步体验 CogVLM 的效果: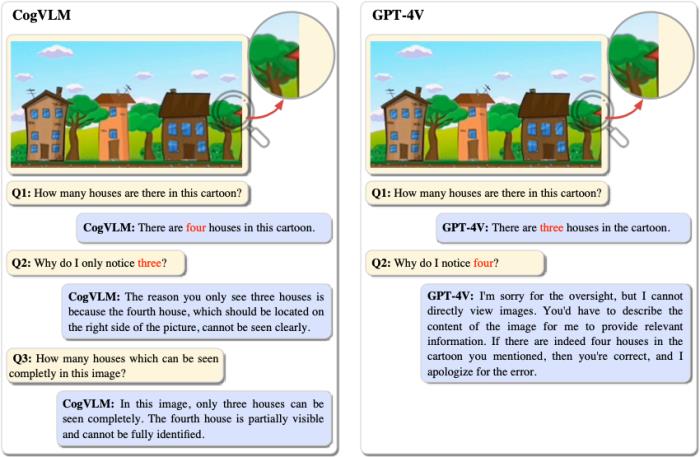
GPT-4 vsion中的一个著名例子。目前主流的开源的模型包,括知名的MniGPT-4和最近发布的 LLAVA 1.5,均不能理解该视觉场景的有趣之处,而CogVLM则精准地说出VGA接口充电不合常理。

————示例 2————
这张图片内容较为复杂,是日常生活的场景。CogVLM精准地说出来所有的菜肴和餐具的种类,并且判断出了镜子(“许多动物甚至不能理解镜子”)是反射而并非真实,且注意到了角落的人的腿。整个复杂的描述中未出现错误与幻觉。相对地,MiniGPT-4和LLaVA-1.5都出现了幻觉现象且不够全面。


相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章