新火种
2023-11-13
新火种
2023-11-13 


机器学习:处理不平衡数据的5个重要技术
【IT168 技术】数据分布不平衡是机器学习工作流中的一个重要问题。所谓不平衡的数据集,意思就是两个类中一个类的实例比另一个要高,换句话说,在一个分类数据集之中,所有类的观察值的数量是不一样的。这个问题不仅存在于二进制类数据中,也存在于多类数据中。本文中将列出一些重要的技术,帮助您处理不平衡的数据。 1、过采样(Oversampling)此技术用于修改不相等的数据类以创建平衡的数据集。当数据量不足时,过采样法通过增大稀有样本的大小来达到平衡。过采样的一种主要技术是SMOTE(合成少数过采样技术,Synthetic Minority Over-sampling TEchnique)。在这种技术中,少数类是通过生成合成算例而不是通过替换来进行过采样的,而且对于每一个少数类的观察值,它都计算出k最近邻(k-NN)。但这种方法仅限于假设任意两个正实例之间的局部空间属于少数类、训练数据不是线性可分的情况下,这种假设可能并不总是正确的。根据所需的过采样量,随机选择k-NN的邻域。
1、过采样(Oversampling)此技术用于修改不相等的数据类以创建平衡的数据集。当数据量不足时,过采样法通过增大稀有样本的大小来达到平衡。过采样的一种主要技术是SMOTE(合成少数过采样技术,Synthetic Minority Over-sampling TEchnique)。在这种技术中,少数类是通过生成合成算例而不是通过替换来进行过采样的,而且对于每一个少数类的观察值,它都计算出k最近邻(k-NN)。但这种方法仅限于假设任意两个正实例之间的局部空间属于少数类、训练数据不是线性可分的情况下,这种假设可能并不总是正确的。根据所需的过采样量,随机选择k-NN的邻域。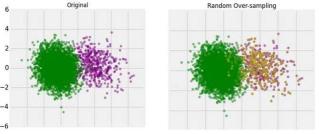 优势·无信息损失·减少过度采样引起的过拟合。深入研究SMOTE技术,请点击这里。2、欠采样(Undersampling)与过采样不同,这种技术通过减少类的数量来处理一个不平衡的数据集。分类问题有多种方法,如聚类中心和Tomek links。聚类中心方法用K-means算法的聚类中心代替样本的聚类;Tomek link方法去除类之间不需要的重叠,直到所有最小距离的最近邻都属于同一个类。
优势·无信息损失·减少过度采样引起的过拟合。深入研究SMOTE技术,请点击这里。2、欠采样(Undersampling)与过采样不同,这种技术通过减少类的数量来处理一个不平衡的数据集。分类问题有多种方法,如聚类中心和Tomek links。聚类中心方法用K-means算法的聚类中心代替样本的聚类;Tomek link方法去除类之间不需要的重叠,直到所有最小距离的最近邻都属于同一个类。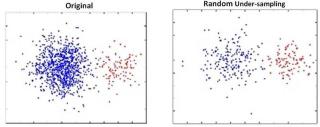 优势·可以通过减少训练数据集的数量来改进运行时。·有助于解决记忆问题有关欠采样的更多信息,请单击此处。3、成本敏感学习技术(Cost-Sensitive Learning)成本敏感学习(CSL)通过最小化总成本来将误分类成本加入考虑因素中,这种技术的目标主要是追求将实例分类为一组已知类时的高精度,它在机器学习算法中发挥着重要的作用,包括现实数据挖掘类应用。该方法将FP(False Positive)、FN (False Negative)、TP (True Positive)、TN (True Negative)的成本表示为成本矩阵,如下图所示,其中C(i,j)表示对实例进行分类的误分类成本,“i”为预测类,“j”为实际类。这是一个二元分类的成本矩阵的例子。
优势·可以通过减少训练数据集的数量来改进运行时。·有助于解决记忆问题有关欠采样的更多信息,请单击此处。3、成本敏感学习技术(Cost-Sensitive Learning)成本敏感学习(CSL)通过最小化总成本来将误分类成本加入考虑因素中,这种技术的目标主要是追求将实例分类为一组已知类时的高精度,它在机器学习算法中发挥着重要的作用,包括现实数据挖掘类应用。该方法将FP(False Positive)、FN (False Negative)、TP (True Positive)、TN (True Negative)的成本表示为成本矩阵,如下图所示,其中C(i,j)表示对实例进行分类的误分类成本,“i”为预测类,“j”为实际类。这是一个二元分类的成本矩阵的例子。 优势·该方法避免了参数的预先选择和决策超平面的自动调整。深入了解CSL技术,请单击这里。4、集成学习技术(Ensemble Learning)这个基于集成的方法是处理不平衡数据集的另一种技术,集成技术是将多个分类器的结果或性能结合起来,以提高单个分类器的性能。该方法通过装配不同的分类器来修改单个分类器的归纳能力。它主要结合了多个基础学习器的输出。集成学习有多种方法,如Bagging、Boosting等。Bagging(Bootstrap Aggregating),试图在较小的数据集上实现相似的学习器,然后取所有预测的平均值。Boosting (Adaboost)是一种迭代技术,它根据最后的分类调整观察值的权重。该方法减少了偏置误差,建立了较强的预测模型。优势·这是一个更稳定的模型·预测结果更好了解有关此技术的更多信息,请单击此处。5、组合类方法(Combined Class Methods)该方法将各种方法组合在一起,能够更好地处理不平衡数据。例如,SMOTE可以与其他方法进行组合,如MSMOTE (Modified SMOTE)、SMOTEENN (SMOTE with edit Nearest neighbor)、SMOTE- tl、SMOTE- el等,来消除不平衡数据集中的噪声。MSMOTE是SMOTE的改进版本,它将少数类的样本分为三类,如安全样本、潜伏噪声样本和边界样本。优势·不丢失有用信息·很好的归纳原文作者:AMBIKA CHOUDHURY 来源:Analytics India Magazine
优势·该方法避免了参数的预先选择和决策超平面的自动调整。深入了解CSL技术,请单击这里。4、集成学习技术(Ensemble Learning)这个基于集成的方法是处理不平衡数据集的另一种技术,集成技术是将多个分类器的结果或性能结合起来,以提高单个分类器的性能。该方法通过装配不同的分类器来修改单个分类器的归纳能力。它主要结合了多个基础学习器的输出。集成学习有多种方法,如Bagging、Boosting等。Bagging(Bootstrap Aggregating),试图在较小的数据集上实现相似的学习器,然后取所有预测的平均值。Boosting (Adaboost)是一种迭代技术,它根据最后的分类调整观察值的权重。该方法减少了偏置误差,建立了较强的预测模型。优势·这是一个更稳定的模型·预测结果更好了解有关此技术的更多信息,请单击此处。5、组合类方法(Combined Class Methods)该方法将各种方法组合在一起,能够更好地处理不平衡数据。例如,SMOTE可以与其他方法进行组合,如MSMOTE (Modified SMOTE)、SMOTEENN (SMOTE with edit Nearest neighbor)、SMOTE- tl、SMOTE- el等,来消除不平衡数据集中的噪声。MSMOTE是SMOTE的改进版本,它将少数类的样本分为三类,如安全样本、潜伏噪声样本和边界样本。优势·不丢失有用信息·很好的归纳原文作者:AMBIKA CHOUDHURY 来源:Analytics India Magazine
1、过采样(Oversampling)此技术用于修改不相等的数据类以创建平衡的数据集。当数据量不足时,过采样法通过增大稀有样本的大小来达到平衡。过采样的一种主要技术是SMOTE(合成少数过采样技术,Synthetic Minority Over-sampling TEchnique)。在这种技术中,少数类是通过生成合成算例而不是通过替换来进行过采样的,而且对于每一个少数类的观察值,它都计算出k最近邻(k-NN)。但这种方法仅限于假设任意两个正实例之间的局部空间属于少数类、训练数据不是线性可分的情况下,这种假设可能并不总是正确的。根据所需的过采样量,随机选择k-NN的邻域。优势·无信息损失·减少过度采样引起的过拟合。深入研究SMOTE技术,请点击这里。2、欠采样(Undersampling)与过采样不同,这种技术通过减少类的数量来处理一个不平衡的数据集。分类问题有多种方法,如聚类中心和Tomek links。聚类中心方法用K-means算法的聚类中心代替样本的聚类;Tomek link方法去除类之间不需要的重叠,直到所有最小距离的最近邻都属于同一个类。优势·可以通过减少训练数据集的数量来改进运行时。·有助于解决记忆问题有关欠采样的更多信息,请单击此处。3、成本敏感学习技术(Cost-Sensitive Learning)成本敏感学习(CSL)通过最小化总成本来将误分类成本加入考虑因素中,这种技术的目标主要是追求将实例分类为一组已知类时的高精度,它在机器学习算法中发挥着重要的作用,包括现实数据挖掘类应用。该方法将FP(False Positive)、FN (False Negative)、TP (True Positive)、TN (True Negative)的成本表示为成本矩阵,如下图所示,其中C(i,j)表示对实例进行分类的误分类成本,“i”为预测类,“j”为实际类。这是一个二元分类的成本矩阵的例子。优势·该方法避免了参数的预先选择和决策超平面的自动调整。深入了解CSL技术,请单击这里。4、集成学习技术(Ensemble Learning)这个基于集成的方法是处理不平衡数据集的另一种技术,集成技术是将多个分类器的结果或性能结合起来,以提高单个分类器的性能。该方法通过装配不同的分类器来修改单个分类器的归纳能力。它主要结合了多个基础学习器的输出。集成学习有多种方法,如Bagging、Boosting等。Bagging(Bootstrap Aggregating),试图在较小的数据集上实现相似的学习器,然后取所有预测的平均值。Boosting (Adaboost)是一种迭代技术,它根据最后的分类调整观察值的权重。该方法减少了偏置误差,建立了较强的预测模型。优势·这是一个更稳定的模型·预测结果更好了解有关此技术的更多信息,请单击此处。5、组合类方法(Combined Class Methods)该方法将各种方法组合在一起,能够更好地处理不平衡数据。例如,SMOTE可以与其他方法进行组合,如MSMOTE (Modified SMOTE)、SMOTEENN (SMOTE with edit Nearest neighbor)、SMOTE- tl、SMOTE- el等,来消除不平衡数据集中的噪声。MSMOTE是SMOTE的改进版本,它将少数类的样本分为三类,如安全样本、潜伏噪声样本和边界样本。优势·不丢失有用信息·很好的归纳原文作者:AMBIKA CHOUDHURY 来源:Analytics India Magazine 相关推荐




- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。