新火种
2023-11-27
新火种
2023-11-27 


一份全面评测大模型的综述
在“百模大战”时代,模型种类多样,参数规模不断提升,行业应用不断拓展,整体来看,AI模型正在重构产业格局。
虽然目前市场上发布的AI模型都叫“大模型”,但参数量被默认为是大模型、小模型的界定因素之一。百度集团副总裁侯震宇表示,10亿参数的模型就叫大模型。但现在的大模型参数动辄上千亿。
根据科技部2023年的统计,中国10亿参数规模以上的大模型已发布79个,而美国则超过了100个。
中国到底需要什么大模型?各大模型的性能如何?大模型技术的产业成熟和应用落地如何?大模型有哪些实践案例,存在的技术挑战和将来发展如何?
在大模型快速发展的今天,我们更需深入认识大模型的不足,预知和防范大模型带来的安全挑战和风险,针对大模型的全方位评测变得极具重要。大模型评测研究可以引导大模型朝着更健康和更安全的方向发展,让大模型的发展成果惠及全人类。
今天来看一篇关于大模型评测的综述论文,共有 111 页,其中正文部分 58 页,引用了 380 余篇参考文献。论文着重解决LLMs在知识与能力评测、对齐评测和安全评测方面的问题。

除了对这三个方面的评测方法和基准的全面审查外,论文还收集了关于LLMs在专业领域表现的评价汇编,并讨论了涵盖LLM在能力、对齐、安全和适用性方面的评测的综合评测平台的构建。
本论文旨在激发对LLMs评测的进一步研究兴趣,最终使评测成为引导LLMs负责任发展的基石。希望通过最大化社会利益和最小化潜在风险的方式塑造LLMs的发展方向。
如下图所示,论文将大模型评测按照评测维度的不同分为了 5 个评测类别:(1)知识和能力评测,(2)对齐评测,(3)安全评测,(4)行业大模型评测,(5)(综合)评测组织。
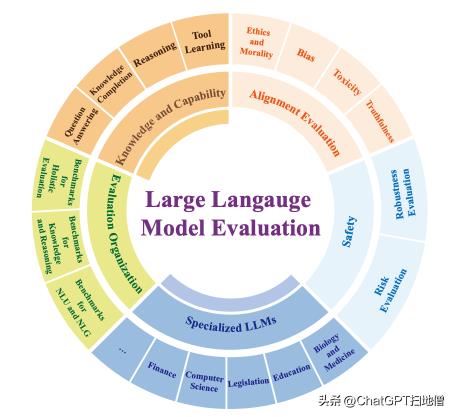
图注:大模型评测研究中的 5 个主要评测类别及其子类别
01
知识和能力评测
大模型的知识和能力评测非常重要,关乎大模型是否真正适配实际业务场景。论文细致地将它分为问答能力评测、知识补全能力评测、推理能力评测及工具学习能力评测四个不同的方面,并梳理了相关的评测基准数据集、评测方法和评测结果。
就推理能力来说,复杂推理包括理解和有效利用辅助证据和逻辑框架来推断结论或促进决策的能力。在划分评估范围的过程中,论文建议将现有的评估任务分为四个主要领域,每个领域都根据推理过程中所涉及的逻辑和证据要素的性质而有所区别。这些类别分别为常识推理、逻辑推理、多跳推理和数学推理。
工具学习指的是使人工智能能够操纵工具的基础模型,它可以为现实世界的任务提供更有效、更精简的解决方案。LLM 可以执行与现实世界交互的基础操作,例如操纵搜索引擎、在电子商务网站上购物、在机器人任务中进行规划等等。模型的工具学习能力可分为操作工具的能力和创造工具的能力。
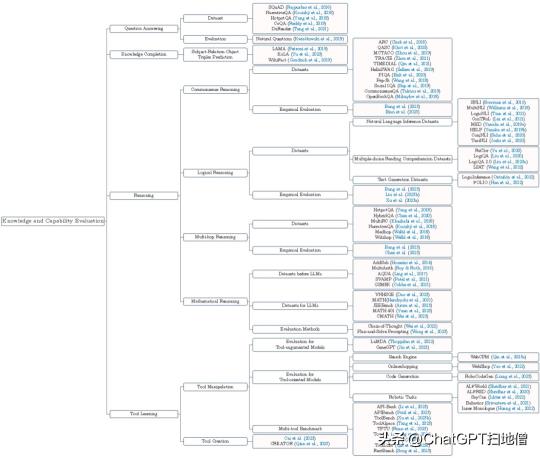
图注:大模型知识和能力评测
02
对齐评测
尽管经过指令调整的 LLMs 表现出了令人印象深刻的能力,但这些对齐的 LLMs 仍然存在注释者的偏见、迎合人类、幻觉等问题。为了全面了解 LLMs 的对齐评测,论文讨论道德、偏见、毒性和真实性等问题,如下图所示。
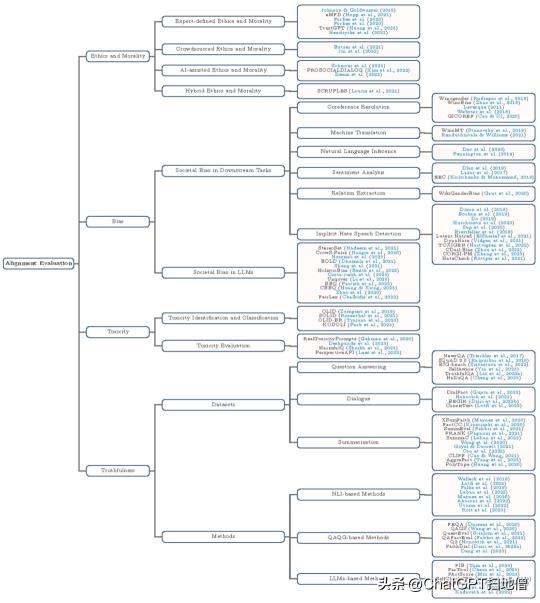
图注:大模型的对齐评测
以伦理道德评测为例,对大模型的伦理道德评测旨在评估LLMs是否具备伦理价值调整能力,以及是否产生了可能偏离伦理标准的内容。虽然确定道德类别的标准存在很大差异,但综述根据评价准则的不同将道德和伦理评测分为四个部分:
基于专家定义的伦理道德评测,专家定义的伦理道德是指由专家分类的伦理道德,通常在学术书籍和文章中提出。基于众包的伦理道德评测,这种方式定义的伦理道德都是由众包工作者建立的,他们无需专业指导或培训,仅凭自己的喜好来判断伦理道德。基于人工智能辅助伦理道德评测,人工智能辅助伦理与道德是指在确定伦理类别或构建数据集的过程中使用人工智能来辅助人类。基于混合模式(如专家定义 + 众包方式)的伦理道德评测,这既包括由专家创建的伦理准则数据,也包括由大众确定的伦理准则数据03
安全评测
根据目前的研究,将 LLMs 安全性评测大致分为两类:鲁棒性评测(衡量 LLMs 在面对干扰时的稳定性)和风险评测(检查高级/通用 LLMs 行为并将其作为代理进行评估),其对应的思维导图如下图所示。
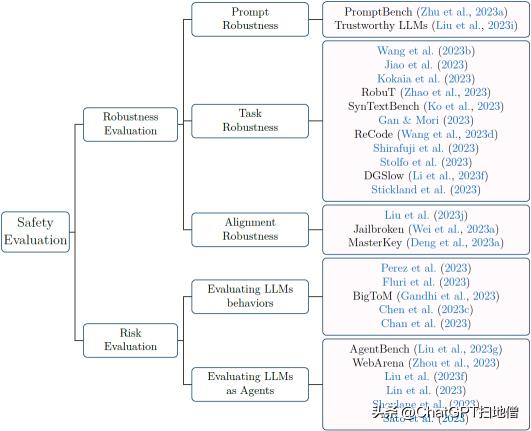
图注:大模型安全评测
04
行业大模型评测
LLMs在众多下游任务中表现出卓越的性能,使其在各种专业领域中不可或缺。这些领域包括生物和医学、教育、立法、计算机科学和金融等不同领域。这篇综述深入探讨了 LLM 在这些领域的最新成就,如下图所示。不过,我们必须承认,挑战和局限性依然存在。
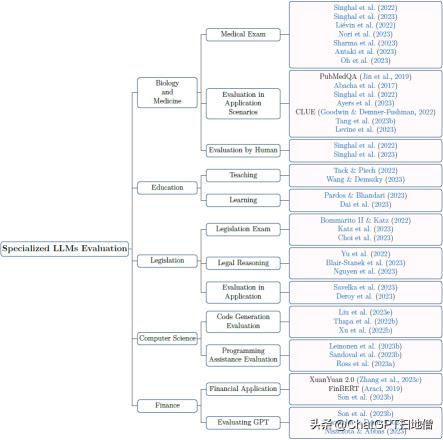
图注:行业大模型评测
05
(综合)评测组织
这篇综述从知识、推理、安全等不同角度讨论了对 LLM 的评估。由于 LLM 可用于非常广泛的任务,因此论文希望从多个角度和任务对 LLM 进行全面评估。这就需要在一个综合基准中组织多个评估任务。
该综述对评测组织研究进行了全面梳理,并将相关的综合性评测基准归类为两种:
由自然语言理解和自然语言生成任务组成的评测基准,如早期的 GLUE、SuperGLUE 和近期的 BIG-Bench 等;由人类各学科考试题组成的学科能力评测基准,其目的是评估大模型的知识能力,如 MMLU、C-Eval、MMCU 和 M3KE 等。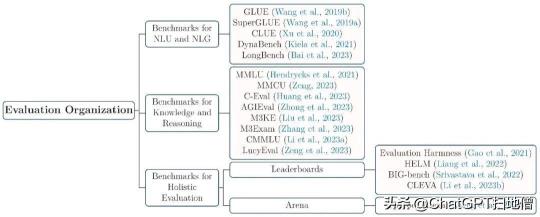
图注:评测组织
除此之外,该综述还总结了不同模型在学科能力评测基准上的表现,并分析和探讨了测试集样本所属的语言、模型的参数规模、指令微调和思维链等因素对模型效果的影响。
该综述还介绍了评测平台、排行榜以及大模型竞技场,这些排行榜的评测数据集通常也由多个任务的评测数据集共同组成。
Chatbot Arena(大模型竞技场):引入了 Elo 评分机制对大模型进行打分和排名,在计算 Elo 评分时,由人类对大模型生成的回复进行投票以选出质量高的回复。Leaderboards:(1)Evaluation Harmness 框架提出了一种连贯而标准化的方法,用于评估生成式 LLMs 在 few-shot 下的多种不同评估任务。(2)BIG-bench:除了常规任务外,BIG-bench(Srivastava 等人,2022 年)还引入了一个扩展的、多方面的基准,在具有挑战性的条件下对 LLM 进行严格评估。(3)HELM:引入了一个自上而下的分类框架,涵盖 16 个不同场景和 7 个衡量标准。(4)CLEVA:通过注释大量新数据,实施复杂的抽样策略,以确保根据最新一轮评估的结果定期更新排名顺序。这种方法有助于长期保持基准的完整性和相关性,同时将数据泄漏的风险降至最低。LLMs评测的最终目标是确保其符合人类价值观,从而促进有益、无害和诚实的模型的发展。然而,随着 LLMs 能力的快速发展,现有的 LLMs 评估方法在全面了解 LLMs 的能力和行为方面显然存在不足。为了深入了解模型行为,更好地防范潜在危害,论文认为 LLMs 评测应与 LLMs 能力同步发展,从而为模型改进铺平道路,并推动 LLMs 的进一步发展。
为此,论文讨论了 LLMs 评测的几个未来方向,包括风险评测、智能体评测、动态评测和面向增强的评测。论文希望这些方向将有助于开发更先进、更符合人类价值观的 LLM。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。