新火种
2025-05-20
新火种
2025-05-20 


腾讯云论文入选全球顶会SIGCOMM,解决云计算大模型网络技术痛点
5月19日消息,全球计算机网络领域顶级会议SIGCOMM近期公布了2025年度首批入选论文名单,腾讯云网络团队提交的两篇论文双双入选。两项技术分别攻克了超大规模云计算网络性能瓶颈及万亿参数大模型训练效率难题,标志着腾讯云在云网络和AI基础设施领域达到国际领先水平。
SIGCOMM以高影响力和严苛的录取率著称。自1970年创办以来,SIGCOMM推动了TCP/IP、SDN、P4可编程网络等里程碑网络技术的诞生。SIGCOMM论文被引用率极高,常成为教科书案例。
创新架构设计,支撑超大规模云网络加速论文《FORNAX:基于智能网卡的大规模VPC会话加速方案》展现了腾讯云基于自研银杉智能网卡实现超大规模公有云网络加速的创新解决方案。

腾讯云自研银杉智能网卡
智能网卡是云网络加速的重要组件,其加速机制依赖于流表——包含匹配条件和执行策略的规则库,来指导数据包的转发、安全控制及网络优化。因此流表的管理效率,直接关系着网络的吞吐能力。
传统方法是依靠软件来管理硬件中的流表。但在流量激增时,软件需频繁更新千万级流表,易因处理延迟引发丢包或硬件加速策略失效;软件还需要周期性遍历流表检查状态,效率低且大量占用CPU资源,影响性能。另外,硬件中保存流表的单元容易遇到物理失效,也会影响数据转发。
腾讯云提出的FORNAX方案是一种硬件原生流表管理架构。与传统软件管理方式不同,FORNAX将单向的流表管理升级为双向的会话管理,聚合会话中的连接状态、策略版本、校验码等元数据,使硬件具备自主感知流量生命周期和策略变化的能力。软件也不再保存所有流表的细节,而是只保留必要信息,需要时再快速恢复,大大节省资源开销。

腾讯云硬件原生流表管理架构
为了提高整个系统的容错性,FORNAX还增加了纠错码校验和硬件转发挂死检测机制,一旦识别异常事件,硬件会自动通知软件系统进行处理,替代软件方式下的全表扫描,做到精准响应。同时,软件系统也会定期巡检硬件会话,支持会话、端口、VPC等多维度和高精度的故障主动发现并切换CPU软件转发的能力,能够在业务无感的情况下处理掉错误。
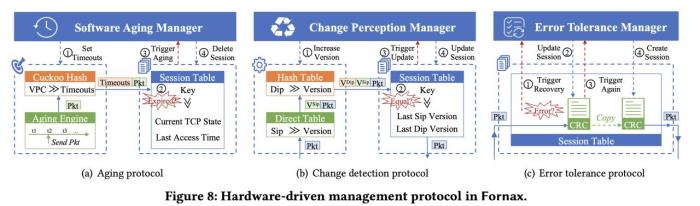
腾讯云软硬协同会话表容错管理协议
目前,FORNAX已经在数百万台云服务器上运行了两年多,服务于数十亿用户的网络流量,并保持因为硬件流表失效引发宕机的0记录,证明了其有效性和可靠性。
聚焦大模型场景,打造高性能网络基础设施另一篇入选论文《星脉:大语言模型训练的数据中心基础设施》则介绍了腾讯云专为大模型训练和推理构建的高性能网络基础设施技术方案。
当前,大模型参数从百亿进化到万亿级,底层训练需要超大规模 GPU 集群。但国内GPU资源紧张和性能掣肘,传统数据中心在网络架构和高密度部署上存在短板,以及大规模集群中软硬件故障多和定位难等问题,都对超大规模高性能算力集群建设和维护带来了不小挑战。
腾讯云星脉网络基础设施方案在网络架构、硬件、以及集群监控等层面都做了针对性优化。
在网络架构层,星脉提出了同轨互联架构,让同机柜的 GPU 优先在同Pod内直连通信,减少跨 Pod 通信中的性能损耗;同时,星脉支持单Pod 6.4万块 GPU互联,全集群51.2万块 GPU组网。在网络设计上,星脉采用带宽无瓶颈思路,每一层网络带宽都100%匹配GPU需求。

星脉组网架构
星脉还提出全新电源管理与冷却方案,解决了高密度GPU部署带来巨大功耗和散热压力,提升部署密度,并降低数据中心PUE。针对AI算力集群故障问题,星脉打造智能监控系统给数据中心安装“全身CT”,实现从硬件到软件全监控,能将集群故障定位从几天缩短到几分钟。
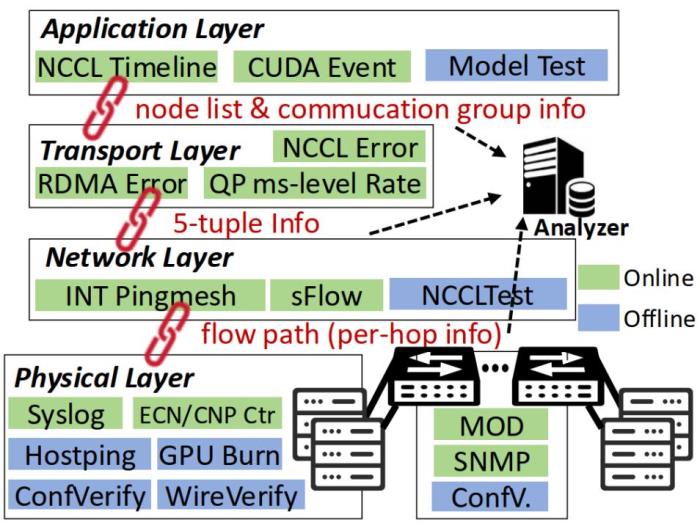
星脉监控系统
同时,星脉打造的性能预测框架,能够秒级生成每个算子的执行时间,结合实际监控数据校准,能够保持极小的性能预测误差,帮助工程师提前发现瓶颈。
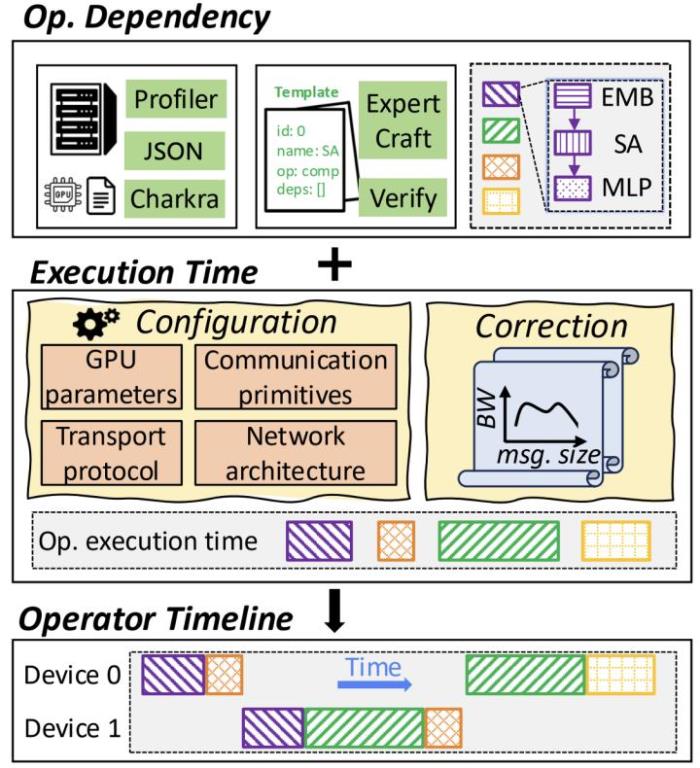
星脉性能预测框架
经过实际部署检验,腾讯云星脉在提升训练效率、降低故障定位时间和提高能源效率方面都表现出色。目前,腾讯云星脉也已经支持了腾讯混元、腾讯元宝、腾讯ima等腾讯自研业务,也服务了大量的产业客户。
不久前,腾讯云星脉团队针对DeepSeek开源的DeepEP通信框架进行深度优化,使其在多种网络环境下均实现显著性能提升。相关技术方案也获得了DeepSeek公开致谢,称这是一次“huge speedup”代码贡献。
相关推荐



- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章